OBSにマルチ入力のあるオーディオインターフェイスを認識させる方法
TL;DR
- 通常のOBSではオーディオインターフェイスのLine1, 2にしか対応していない
- obs-asioとobs 27.0を使用するとマルチ入力に対応できる
OBSの対応範囲
OBS上でオーディオインターフェイスを使った音声入力を行う場合、Line1/2を使うことで実現できるが、Line 3/4やそれ以外のポートからの入力を受け付けていない。
自分が使っているSteinberg UR824ではフォン入力が8ポート分あるが、3~8までの入力が音声ミキサーに反応してくれないので困った😂😂
解決策
obs-asioと呼ばれる、obsにasioデバイスを対応させるプラグインをインストールすることで解決できる。
obs-asio
githubのリリースタグから最新のexeファイルをDLしてインストールするだけでおk。
もしobsのインストール先を変更している場合は、インストール途中にobsのディレクトリを選択する画面が出るので適宜変更しておく。
obs 27.0
最新のobs-asio(3.1.0)はobs 27.0にしか対応していないので注意。
またobs 27.0はプレリリースであるため、こちらもgtihubのリリースタグからインストールする。
OBS上の設定
obs-asioが正常にインストールできたら「ソース」から「追加」-->「ASIO Input Capture」があるはずなので、選択する。

プロパティから使用しているオーディオインターフェイスとOBS Channel 1/2から入力に使いたい音声ポートを選択する。

選択できたら、オーディオインターフェイスからの入力にobsの音声ミキサーが反応してくれるはず🥳🥳🥳
【論文読み】Enhanced Local Texture Feature Sets for Face Recognition Under Difficult Lighting Conditions
TL;DR
- 照度変化に頑強とされているLocal Binary Pattern(LBP)よりも頑強な手法を提案
- シンプルな前処理方法により、3種類のデータセットでSoTAを達成
- 提案手法に加えて、画像間の距離計算を工夫したことで検索のパフォーマンスを向上することができた
1. Introduction
※この論文が発表されたのは2010年であるため、CNNで画像認識を行ったAlexNet(2012年)よりも前のになります
顔認識において重要なのは、様々な環境において顔画像の照度変化、年齢、パーツ(鼻の位置etc,...)の形状情報が頑強であることである。これらから得られる特徴量を元に認識を行うので、例えば同じ顔なのに暗い環境と明るい環境で違う顔として認識されるのは避けたい。
そこで、これまれまでに以下のような記述子が用いられてきた。
- Gabor wavelets
- Local auto correlation filters
- Local Binary Patterns(LBP)
この論文でLBPについて注目し、その特徴と改善案についてまとめた。
2. LBPの特徴
LBP特徴量については、わかりやすい記事がたくさんあるので、ぜひ。
http://compsci.world.coocan.jp/OUJ/2012PR/pr_15_a.pdf
手法としては画像をグレースケールに変換し、注目画素値と周辺の8画素値を比較して数値が高ければ1、低ければ0をラベリングして符号化(2進数-->10進数)するだけの処理になる。
注目画素を移動させながら符号化された値をヒストグラム化することで、その画像のLBP特徴量を得ることができる。

ノンパラメトリックでシンプルな手法ながら、高速で照明の変化に頑強であるためCNNが流行する前の画像処理ではよく使われていた。
照明変化に頑強である理由として、画像の局所領域の照明に変化があってもLBPの符号化に大きな影響を与えないからだ。例えば、Fig. 1の画素値に100を足しても、周辺画素との大小関係は変化しないのでLBP自体には影響はないことが分かる。
言い換えると、LBPは単調増加なグレースケールの変化という仮定の元に置いている。
そのため、LBPを算出する際には特に前処理の工程を挟む必要はないと考えられていた。
しかしながら、筆者の実験では照明変化の分散が大きいデータセットではLBPが良いパフォーマンスを発揮できていないことが示唆された。
また、LBPは顔の首や額部分などの一様に分布している領域でのランダム/量子化ノイズに弱い。
そこで本論文ではLBPを拡張したLocal Ternary Patterns (LTP)を用いることにした。
3. Related works
同様な問題設定を解く手法として、Self Quotient Image model (SQI)、Logarithmic Total Variation (LTV) 、smoothing, and Gross & Brajovic (GB)が紹介しているが詳細は省く。
4. Local Ternary Patterns (LTP)
LTPはLBPの拡張であり、2値で表現するLBPとは違い+1,0,-1の3値で表現する。
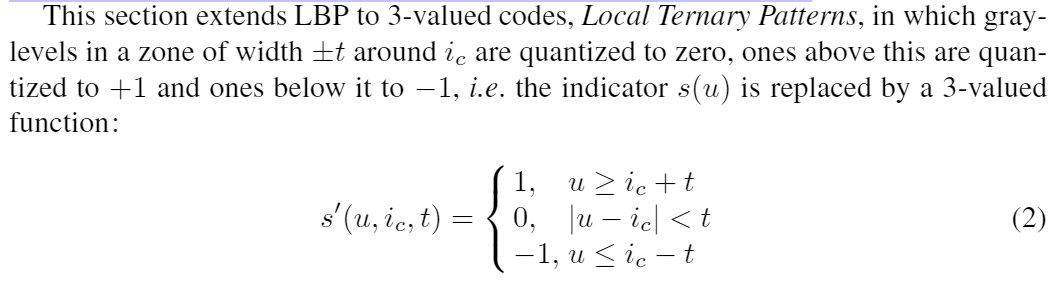
uが注目画素値、i_cが周辺画素値、tが任意で設定できる閾値になっている。
このt値を決めることがこの手法のキモでもあり、u-tとu+tに間を持たせることでよりノイズに対してより頑強になる。
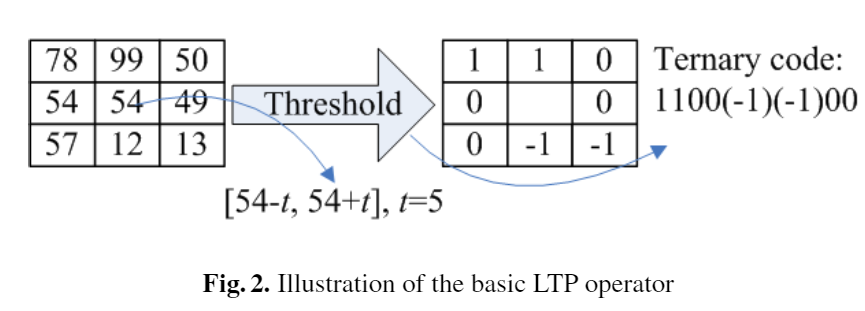
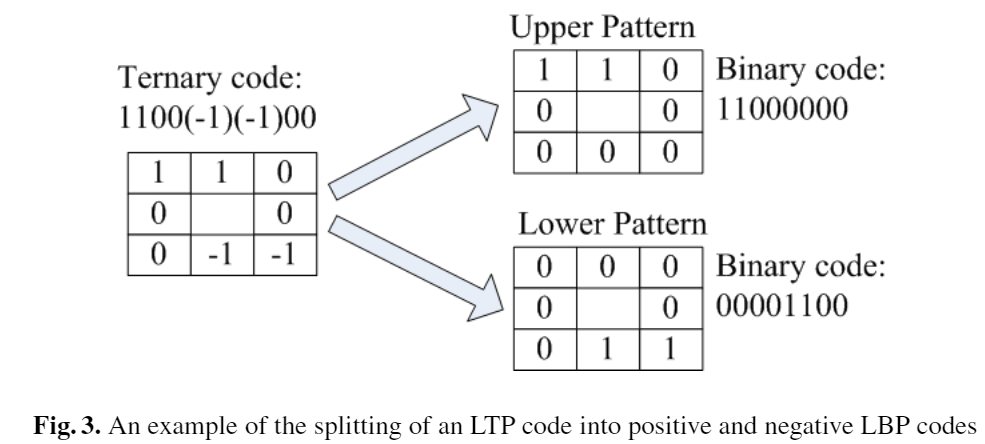
LBPは2値を10進数に変換したが、LTPは-1を含んでおりそのままでは符号化の扱いに困ることが分かる。 そこで、以下の図のように正値を含むパターン(Upper Pattern)と負値を含むパターン(Lower Pattern)に分けて符号化し、それぞれでヒストグラム計算したものを最後に組み合わせることで解決している
5. Proposed Method
5.1 Distance Transform Based Similarity Metric(DT)
既存研究[1]のLBPを使った手法では、顔画像をいくつかのグリッドに分割してそれぞれのグリッド中でLBPを計算し以下の式を用いて類似度を計算している。
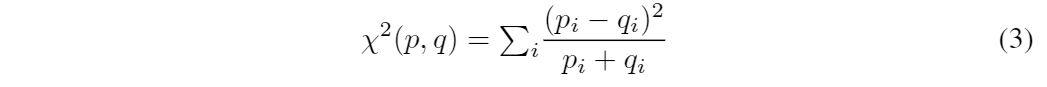
しかし、この手法では以下の問題点が挙げられる。
- 分割する境界が必ずしも顔特徴と一致しない(規則的にグリッドを作ることに対して疑問がある)
- 境界によって急激な空間量子化が起こる
- 位置関係が保持されないため、空間情報が失われる
筆者はLTPが照明や空間情報に微妙な変化を許容した特徴量だと考えるなら、画像Xの各画素のLTP値が画像Yと近い位置に現れるかを画像間の距離に応じて重み付けするのが適切だと考えた。
この考え方は集合間の距離計算に使われるハウスドルフ距離に似た手法である。
本論文で提案されている手法は以下の通りである。
- 入力画像Xにおける各画素のLTP値を求める
- LTPの値(論文上のコードk)ごとに2値化した画像b_kを作る
※LTP値が存在する画素を255、それ以外を0とするような画像 - b_kごとにb_k上の各画素とコードkが現れる画素との最小距離を求め、距離画像d_kを作る
※論文では2次元のユークリッド距離を使用
ここでuniform codesを使用する場合は59個の画像が最終的にできあがる。
Uniform Codesの補足(なんで59個になるのか?)
LBP/LTPのバイト列において0->1 or 1->0に変化する回数が最大2回までならそれをUniform Codesと言う。
例えば 00001111, 00110000, 00000000はいずれも変化回数が2以下なのでuniformである。逆に 00110011, 10101010はuniformではない。
LBP/LTPは周辺8画素を取るため、純粋にバイト列を変換すると2^8=256通りになるが、uniformでないものを除去するとこれが59通りにまで圧縮されるため計算削減になる。
59通りの全通りは下記の記事から確認できる。
ステップ1~3を実行した時の任意のコードkにおける実行結果が以下の図である。
左からb_k,、d_k、d_kに閾値τをもたせて2値化させた画像である。

ここで、この距離画像d_Kを使って画像X、Y間の距離関数Dは以下の式で表される。
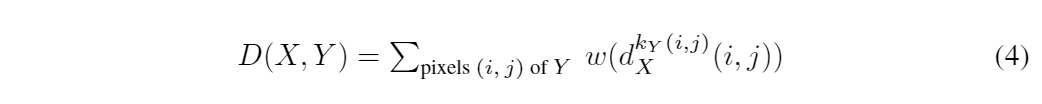
ここで、iとjは画素位置、k_Y(i, j)は画像Yにおけるコードkの値、ωは距離画像を作る際の任意の関数である。
画像Yにおけるコードkが画像Xのコードkのどの位置の分布しているかが、この関数Dから算出できるため、筆者が提案している内容に沿うことが分かる。
例えばk_Y(1, 1) = 0, d^0_k(1, 1) = 0 だとD=0、d^0_k(1, 1)=255 => D>>0になる。
(tex風に書きたい...)
なお、論文上にω関数はガウシアン距離と線形関数の2つが提案されていたが、2つの関数に大きな性能差はなく線形のほうが僅かに性能が良かったと記述されている。
5.2 Illumination Normalization
ここでは筆者が問題提起していた、LBPには前処理はないことについての解決案を記述する。順番に処理実行するようなパイプラインとして定義している。
1. Gamma Correction
画素値Iに対してI^γをかけたものがガンマ補正である。γは[0. 1]までの任意の値で、ディスプレイ等のデバイスの色調整によく使用される。
γ値を1以下にすることで、暗い画素が明るく方向に持ち上げられるため、より画像内の質感を復元することができる。しかし上げ過ぎるとノイズになるため、論文内ではγ=0.2とした。
2. Difference of Gaussian (DoG) Filtering
次のDog Filterをかけることで、ガンマ補正で取り除くことができない急激な照度変化の影響を取り除く。
この影響は主に画像内の低周波数領域におこるため、周波数領域においてハイパスフィルターをかけたら良さそうだが、高周波数はノイズの元となる信号も含まれる。
高周波数領域を取り除いても識別に必要な情報は十分に残るため、ローとハイを同時にカットできるバンドパスフィルターを再現したフィルターが適している。
DoG Filterはバンドパスを再現したフィルターに近いため、この手法に取り入れることにした。
3. Masking
上記2つのフィルターを通してもなお、変化が急激な画素値を持つ場合には別途マスキングが必要となる。
具体的な手法が書かれていないため、スキップ。
4.Contrast Equalization
最後にコントラスト値の正規化を行う。
画像認識においてコントラストに変化があると認識精度への影響があるため、ロバストな推定には重要なステップとなる。
以下の2つの式を用いて正規化を行う。
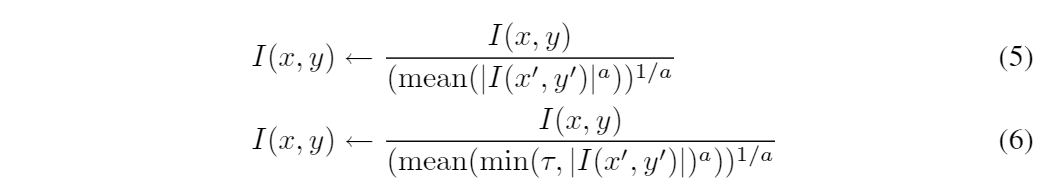
ここでαは大きい画素値を制御するための圧縮値、τは式(5)で発生した大きい値を切り捨てるための閾値となる。論文中でα=0.1、τ=10としている。
式(6)の処理が終わったあとでも極端に大きい値を含んでいる可能性があるため、ハイパボリックタンジェント関数を通すことで[-τ,τ]に抑える。

6. 処理結果例
上記の手法を適用すると、どのような結果になるのかを下記に示す。
Fig. 5が同じ顔画像の照度を変化さえたもののペアであり、この2つの画像で同じような特徴量が得られたら嬉しい。

下記のFig. 5の白枠におけるLBPのヒストグラムである。
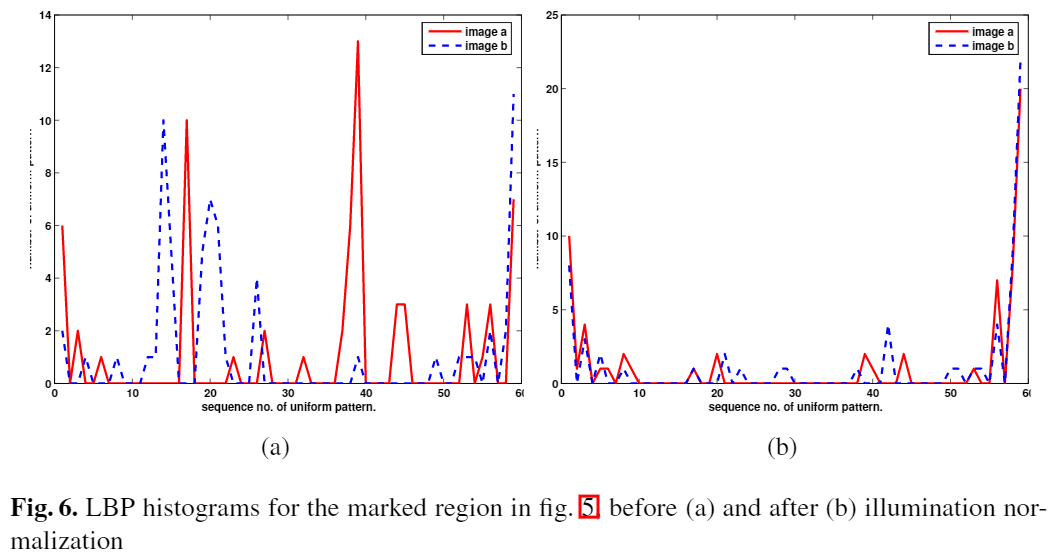
左(a)が手法を適用する前、右(b)が前処理を適用した時の結果だが、(a)のように明らかに突飛つした値が出ていないこと分かる。
処理速度も120×120ピクセルで50[msec]の速度で実現できる。
7. Experiments
3つのデータセットにおいて、以下のパラメーターを用いて実験を行った。
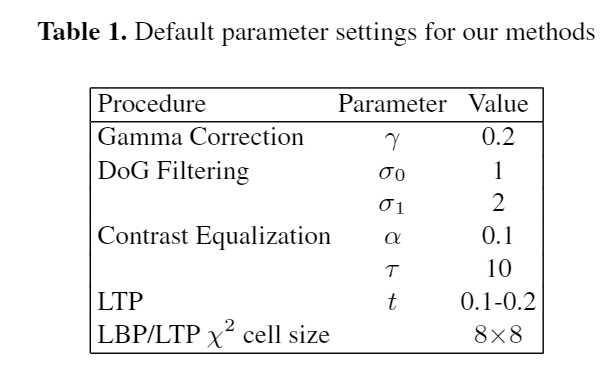
また、論文では各データセットごとに実験結果をまとめている。
7.1 FRGC-104
下記が各手法をと入れたときの認識精度である。
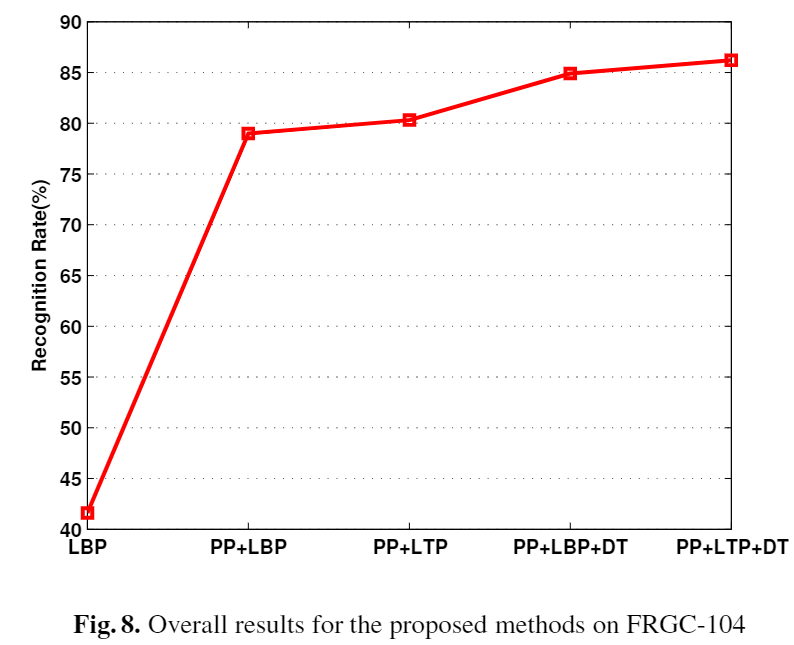
この結果を見ると、単純にLBPを使うよりも前処理のパイプライン(PP)を導入するだけで41% --> 79%に精度が向上している事がわかる。
また、最終的にPP+LTP+DTを使うことで85%近く出ており本手法の有効性が示されている。DTを使用していない時の距離計算は式(3)を用いている。
7.2 Yale-B
Yale-Bは同じ顔画像に対して複数の角度から照明を当てたときのデータセットであり、
下記の図は照明の角度に応じてPPを適用した時の結果である。

また、下記が各手法との精度比較の結果である。
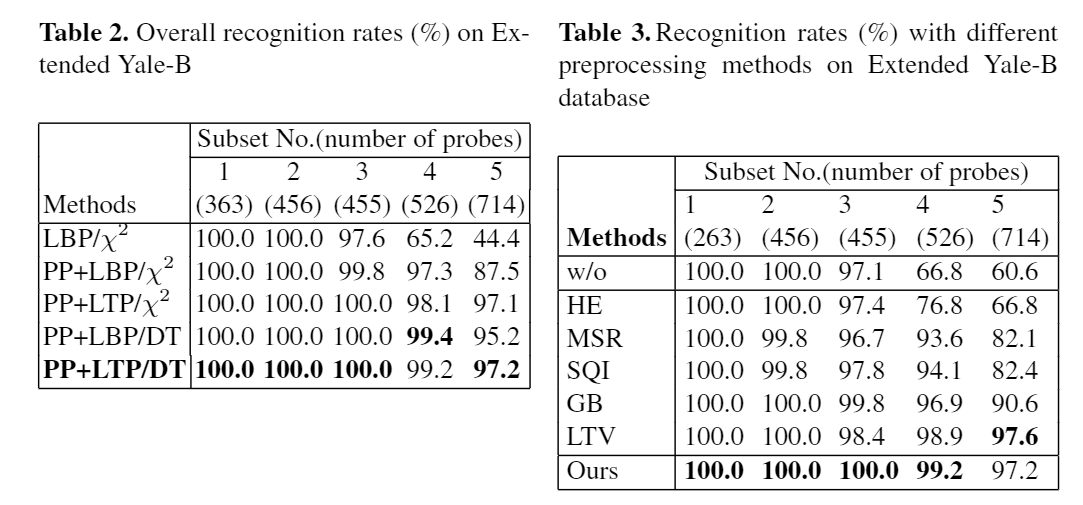
LTVは輝度正規化の一種であるが本手法と比較して300倍遅いとされているため、速度と精度の面でも優位である。
7.2 CMU-PIE
CMU-PIEにおいてもLTVと同様な精度が出ており、Fig. 11のような照度変化においても頑強な特徴量が得られていることが分かる。


8. 参考文献
[1]Ahonen, T., Hadid, A., Pietikainen, M.: Face recognition with local binary patterns. In: Pajdla, T., Matas, J(G.) (eds.) ECCV 2004. LNCS, vol. 3021, pp. 469–481. Springer, Heidelberg (2004)
マルチモーダルなDNNを扱うサービスの本番環境でやらかした話
こんにちは!ころんです。
ちょっと長い間更新をさぼっていましたが、元気にやってます!
よく見たら去年のADTも書いてなかったですね。今年は17日目になります。
TL;DR
- Concatレイヤーの順番が設計したモデルと同じか確認しよう
- モデルをデプロイする前に精度指標以外にもモデルの分布を確認しよう
- 学習時とServingで同じ特徴量をいれたら同じ出力になるか確認しよう
DNNモデル
現在とあるサービスの機械学習のモデリングとその運用の仕事に携わっています。
(詳細はお話できなくて申し訳ないです)
機械学習と言っても様々なドメインがありますが、画像とテーブルデータを用いたDNNを作成しています。いわゆるマルチモーダルですね。
モデルの構造としては画像の畳み込みレイヤーとテーブルデータの特徴の全結合層をそれぞれn次元にまで圧縮、Concatした特徴量を全結合層に通してスカラー値を出すようなモデルです。下記はイメージ図です。
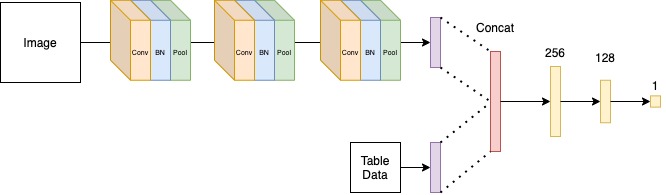
一般的なマルチモーダルモデルのアーキテクチャになっており、学習したモデルをk8sでマネージドしているサーバーにServingし運用しています。
また学習時と推論時では参照しているリポジトリや環境も違うため※1、それぞれが独立して動作するような構成になっています。
※1 学習はGCPのAI Platform、推論時はk8sでtewnsorflowのバージョンは合わせて運用しています
何が起こったか
上記で作成しているモデルは特注なロス関数を組み込んでいるため、学習が終わったらモデルの重みを保存し、Serving時はその重みを読み込んだ上で学習時に使ったモデル構造を再度記述した上で実行しています。
そしてモデルを本番環境にリリースして数日後、社内からモデルが出している値がほとんど変化しないという報告をもらいました。
原因
通常tensorflowでモデルを保存するときは、モデル構造と重みを同時に保存するsaved modelやh5形式が使われます。
しかしながら、今回は重みだけを保存する形式のためサーバーには学習時に使ったコードをコピーして記述する必要がりました。
ここでミスをやってしまいます。
アーキテクチャに戻りますが、Concatする際はTable data + Imageの順番でベクトルの結合をしています。
しかし、サーバー側ではImage + Table dataで結合してしたのが原因で、本来計算される重みが適切にかけられていない事象が発生していました。
コードで表すとこんな感じ。
原因が発覚しすぐに修正PRを出しましたが、裏では様々なバッチが動いており復旧には数日かかりました。
解決策
上記の事象をチームで共有後に解決策を練りました。
1. レビューの強化
PRでサーバーのモデル構造に変更を加える際は、元となる学習のコードもセット(githubのurlで十分)にしてレビューをするように意識付けをしています。
チームでは複数のMLエンジニアがモデルを作成しているので、それぞれのモデルにメインの担当者を付けてダブルチェックする体制も入れました。
2. 検算の仕組みを作る
学習したモデルとサーバーから返される値に違いがないかをチェックする仕組みを作る。これをするとサーバーに実装した前処理にもミスがないか確認できるのでCI/CDに組み込んで自動的に検出できるようにします。
噂ですがTensorflow Pipelineにはそういう機能があるらしい?
3. データの可視化
実は本番環境へデプロイする前に、testに使った真値と予測値との分布の乖離を確認するために可視化した結果をSlackに通知する機能がありました。
今回はたまたまconcatを逆にしても大きな乖離が出なかったため見落としていました。しかし、よく見ると以前学習したモデルに比べてピークになっている値が多くあったため、傾向として捉えることができたはずでした。
そもそも可視化をしていなかれば気づけなかったことが多くあります。単純にモデルのRMSEといったロス指標だけではなく、必要箇所でデータの可視化を行うことが改めて大切であるということが学べた機会でした。
まとめ
今回はDNNのConcatレイヤーでやらかして本番にデプロイしちゃった話を書かせていただきました。問題発覚時は入社して一番冷や汗書いたので、ML系のサービスを運用する際には気をつけましょう。
明日のTUT Advent Calender 18日目はあやふみさんです!
まだタイトルも決まってないようですが、 どうなるんでしょう👀
TUT内で新規サービス開発を始めたお話
こんにちわぁぁああ!!!!こんばんわあああ!!!!ころんでぇぇす!!!
なにこれ?
これはTUT Advent Calendar 2018 15日目の記事とCyberAgent 19新卒 エンジニア Advent Calendar 17日目(早く出してごめんなさい!)の記事です
豊橋技術科学大学 & 東京工科大学合同のアドベントカレンダーであり、CyberAgent 19新卒エンジニアのアドベントカレンダーという一大イベント。
SAPPORO CHU-HI 99.99を飲みながら書かせていただきます。
(クリア グレープフルーツおいしいね)
カラオケは好きですか?
自分の場合、なぜか好きな時と嫌いな時がありますが今は好き!
懐かしのボカロ曲やアニソンを聞くと行きたくなる時期です。
そんな中、ちょっとした問題が自分にはあります。
それは、出せる音域が非常に狭いこと
なので、大体の曲は原キーでは歌えないのでキーの変更を余儀なくされます。
Aメロは歌えるけどサビは無理。部分的にはいけるみたいなのが多いので自分に合うキーを探索、記録には苦労します。
アンケートにご協力いただいた方は見たことがあると思いますが、キー変更をよくする人が12.3%もいてちょっと安心しました。
こちらでやってます-->カラオケに関するアンケート

意地でも原キーな人も割といるんだなと実感
記録は以下のようにiPhoneのメモ機能を用いています(一部をスクショ)

じゃ、記録できるアプリがないのかと言われたら一応あります。
あるけどアプリの完成度としては自分は満足していません。
不満点でいえばこのような感じ
- そもそも落ちる。特定の動作で固まる
- UIが不便。とる大きさと得られる情報量が一致しない
- 音程解析がただのフーリエ変換の測定結果
- アプリの世界観が伝わらない
落ちるアプリはそもそも論外です。それも某大手のアプリですが。
UIと世界観ですが、個々のパーツをそのまま置いただけのような昔の業務用アプリが多いです。
最近のAWA、Tictok、Spotifyもそうですがアプリ1つ1つに世界観があると思っています。アプリを使用しているときの安心感があります。
音域解析ですが、これは本当にただのフーリエ変換で最大ピークをもつ周波数帯をグラフ化したものです。当然それで出せる音域は測定できますが、それが本当に気持ちよく歌える音域ですか?と言われたら違うはずです。
統計的、アカデミックな視点から解析できると思っています
このように(継続して)使ってみようと思うアプリが自分の中ではありませんでした。
無ければ作ればいいじゃない!!
自分のモットーでもあります「無ければ作ればいいじゃない!」
ようは自分の満足するアプリがなければ作ってしまおうという、考えです。
TUT内でサービス開発やってる話聞かないし、作っちゃえ!!
作りたいアプリを説明したうえで、同じTUT内の友達や後輩を巻き込んで一緒にアプリを作ることになりました。
サービス内容
残念ながら今回の記事ではまだ公開できません。
音楽関係であるため著作権に引っかかるなどの制限がありますが、それ以外でできる部分で勝負かけます

アプリの設計案
技術的内容
アプリ開発はスピードが大切だと思います。今できる最善の手で使えるツールがあるのなら積極的に取り入れるべきだと考えました。
AWS Mobile Hub(モバイルアプリケーションの構築、テスト、モニタリング)| AWS
AWS Mobileはユーザー認証を行うAWS Cognito、そのほかAPI gateway, Lamda, S3, DynamoDBなどモバイル開発におけるハブ機能を果たします。
各サービスで無料枠が使えるので
- 開発やリリース初期でも費用の問題がない
- サーバー構築に時間を取られない
- 開発メンバーがパブリッククラウドに触れられるいい機会
と思い選定しました。
また開発メンバーが初学者であるため自分もiOSの勉強をする必要があります。
たまたまチーム発足時にmac miniの発売が発表されたため、ローンを組んでポチりましたw

グラフィック以外はおおむね満足してます。到着が楽しみです。
あと基本チームの連絡はSlackで行い、タスク管理はtrelloで行うことにしました。
使い慣れた & 連携がスムーズにいくという点で決定。
進捗
現在の進捗ですが、コンセプト、アプリの基本機能、アイコンデザイン、サービス名、技術選定の案だしは終わりました。
ただ卒業研究と論文提出の月であるため、本格的に始動するのはクリスマス後になります。
目指すチーム像
ここからは自分がチーム開発するうえで大事にしていることの一部を書きます。
- いい意味でフラットな関係を作る
後輩、同年、先輩間で「年上だから意見を言うのやめよう」とか「自分より技術低くそうだからこの情報共有しなくていいっか」など勝手な価値観で情報共有をしないのはものすごいもったいないことだと思います。
「グループ」ではなく「チーム」なのだから共通の目的、達成すべき目標、アプローチ方法はチーム全員が共有されているべきです。
そのためにも、リーダーである自分からまず情報開示を行に信頼を得るように意識しました。
Gitの使い方、APIの共有、調査報告、etc...ググれば分かるかな?と思う内容も共有します。共有内容+コメント(例:これここで使えそうじゃね?)があればよりgood.
この内容に関してはチームの技量にもよりますが、今回はチーム開発未経験者を含めて考えています。
情報共有とフィードバックを繰り返すことで共有することの大切さが実感でき、少しづつの成果が自信へと繋がり信頼につながると思っています。 - HRT(謙虚・尊敬・信頼)を持つ
謙虚(Humility)、尊敬(Respect)、信頼(Trust)の頭文字をとった言葉です。これはオライリーの「Team Geek」で書かれている、当時のGoogleのチームリーダーが優れたチームを作り上げるときに工夫したものに書かれています。
1つ1つ語ると長くなりますが、要約すると
自分は常に間違っているという可能性を考え、
相手に対する尊敬の気持ちを持ち、
信頼関係を育もう
ということです。詳しくはお酒飲みながらお話ししましょうw
まだまだありますが、このような思考を教えてくれたおすすめ書籍を紹介して終わりにします。
卒業するまであと3か月ちょいでリリースまでもっていけたらと思うのでよろしくお願いします!
明日(いや、実質今日)は、katura46さんですが何を書くのが気になりますね!乞うご期待!!
GTX760のWin10にKerasを導入したのでメモ
ディープラーニングってやつでなんとかして!!!!
ってことで今の環境にニューラルネットワークライブラリであるKerasを導入したのでメモ
ちょっとしたバージョンの違いだけでも動かないので注意してください。
CUDA 9.0 の導入
NVIDIAから出してる並列処理プラットフォームのCUDAを落とします。
現在Ver10まで出ていますが、TensorflowがVer10に対応していないためVer9を導入。
Installer typeはnetoworkだとうまくいかなかったとの情報がありましたが、自分は大丈夫でした。
ちょっと時間がかかりますが、ぱぱっとインストール
cuDNN 7.3.1 の導入
CUDA専用のDNNライブラリのcuDNNを落とします。
これはNVIDIA Developerにあらかじめ登録してないと落とすことができません。また登録申請からアカウントが使えるまで1日待ったので気長にお待ちを
https://developer.nvidia.com/rdp/cudnn-download
バージョンはCUDAに必ず合わせます。CUDA 9.0を入れたので、「..., for CUDA 9.0」のを選択

これはインストーラーではなくフォルダがzipで送られます
cuDNNをCUDAに適用
cuDNNの中に入っているファイルをCUDAにディレクトリにコピーします。
CUDAは標準だと「C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v9.0」に入っているはずです。

cuDNNにはbin, include, libの3つのフォルダがありますが、その中身を上記のCUDAの同じフォルダ名の中にコピー
システム環境変数の確認
ここで一旦、Pathがちゃんと通っているか確認します。
過去にCUDAを入れたことがあったりすると「CUDA_PATH」が違うバージョンを示している場合があるので要注意

Pathにも以下が通っているか確認

Tensorflow 1.11.0 の導入
Pythonの実行するAnacodaとVisual Codeは予めインストールしておいてください。
ちなみにpythonのバージョンは3.5で(3.6でも問題ないはず)
Visual Codeのターミナル画面で仮想環境を立ち上げ「pip install tensorflow-gpu」と打てばインストールしてくれます

Keras 2.2.4 の導入
こちらもターミナル画面で「pip install keras」と打って実行すれば完了
Scipyのバージョン下げ
普通ならばここで簡単なテストを走らせれば動きますが、自分の場合AnacondaかTensorflowを入れる段階でバージョンが違うScipyが入れられたらしくエラーを吐きました。
いろいろ試したところバージョンを1つ下げたもので動いてくれました
- 「conda list」でScipyのバージョンを確認
- pipとcondaで重複していないか確認。重複していれば両方とも消す
- 「pip install scipy==1.0.1」でバージョン指定したのをインストール
パッケージバージョン一覧
とまぁなんだかんだ、以下のようなパッケージになりました。
恐らくもっとすっきりにできると思いますが...

MNISTの分類サンプルの実行
パスとバージョンを確認したうえで、DNN基本であるMINISTの分類を行います。
コードはkerasのサンプルから丸コピーしてください。
.pyコードを実行すると、うまくいけば以下のように現在のエポック、ロス等が表示されます。きちんと GTX 760で回していることも確認できたのでこれでOK!!

ちなみに1エポックで130秒ぐらいかかりました。そこまでdeepではないのでやっぱGTX 760ではこの先も結構時間がかかりそう
Tensorflowのビルド
Tensorflowを自前でビルドする際は別途手順が必要です。
バージョンの対応表は下記リンクの一番下のページにあります
Build from source on Windows | TensorFlow
コンパイルにBazelとMSYSが必要になります。こちらもちゃんとPATHが通っていることを確認してください。
Installing Bazel on Windows - Bazel
またこちらもtensorflowでバージョンが指定されています。なんでもかんでも最新のを選ぶと後々めんどくさいので要注意。
では!いいDNNライフを!
FirebaseのReal Time DatabaseとC#を使ってとりあえずメッセージを送信してみる(1)
こんにちわ、ころんです!
内定先の懇親会で最近「Firebaseまじ神!」「Firebaseまじすごいよ」とよく聞くのでいじってみることにしました。
ファイアァァアアアアア!!!とえいえばTomollow Land 2018でSalvatore Ganacciが無理やり(?)演出係にファイアーさせてるのがツボってますw
Firebaseへの登録
FirebaseはGoogleの傘下にあるので自分はGoogleアカウントでそのまま入れました。
右上にある「コンソールへ移動」をクリックし、「プロジェクトを追加」を選ぶ。

プロジェクトの作成画面で、名前とリージョンを選び作成。今回は「FireBaseChat」で
リージョンはデフォルトでも特に問題ないかと。
Set a project location | Firebase

するとプロジェクトのメイン画面に移ることができました!

認証の設定
Firebaseの魅力にユーザー認証が容易にできることがあります。
わざわざOAuthの認証メソッドを書く必要もないし、Firebaseのプロジェクトごとに認証方法を変えられます。
今回は、分かりやすくするために「匿名」を選びます。

DBの設定
今回はユーザーが投稿したメッセージ等を格納するデータベースの設定を行います。
プロジェクトのメイン画面の左側にある開発から「Database」-->「データベースの作成」を選択するとセキュリティルールの設定に移ります。

今回は「テストモードで開始」を選択。これでDBの設定は終わりです。

DBのシークレットキー
DBへのシークレットキーは、左画面の歯車マークから「プロジェクトの設定」-->「サービスアカウント」-->「以前の承認情報」から取得できます。
しかしながら、DBのシークレットは現在廃止されているようなので今後は「Firebase Admin SDK」からの設定が必要らしいです。
今回の動作には問題ないですが、ここについても調べてみます。

DBのURL
データベースへのURLは「プロジェクトの設定」-->「全般」-->アプリ-->「ウェブアプリにFirebaseを追加」を選択することで確認できます。

C#でコードを書くときにこのDBシークレットキーとURLが必要になるのでメモっておいてください!
C#プロジェクトの作成
みんな大好きVisual StudioからC#のコンソールアプリを作成します。

C#でゴリゴリ書くのもいいですが、せっかくなのでFirebase REST APIをラッパーしたFireSharpを使います。
Visual Studioのパッケージマネージャーコンソールから「Install-Package FireSharp」と打ってインストール。

さてコードですが、ラッパーのおかげで単純にテキストを送信する内容だったらこの程度でできます。
AuthSecretとBasePathにさきほどメモったDBシークレットキーとURLを記入し、実行すると「Hello, Firebase!!!」がDBの「chats/」下に格納されます。
gistd1d30622b27851dbd2a657396cdbfbee
実行後にFirebaseプロジェクトのDatabaseを見ると「Realtime Database」が作成されていることが確認できます。

中身を見ると、先ほど送信したメッセージが格納されています!!
あら簡単!!!
画像は「!!!」の部分が見切れていますがちゃんと入っているので安心を

ちなみにコードのresonceのbodyを見ると各メッセージのIDが確認できます。
まとめ
今回は、Firebaseを使ってクライアントからサーバーにメッセージを格納する処理を作成しました。
単純ですが書いたコードは僅かで実現できたのは確かに便利!
ですがFirebaseの魅力はまだ発揮できていないので、次回からチャットサービスの作成までやっていきますね!!
Philips ソニッケアー Healthy White 先端部修理
いつも愛用しているPhilipsの電動歯ブラシが突然壊れました!
歯ブラシの先端と本体をつなぐ銀色の出っ張りがグラグラになり、超音波の振動が届かず
HealthyWhite ソニッケアー ヘルシーホワイト HX6719/43 | Sonicare

保証書もどっかいったし、新しく買うのもなんかもったいない。
本体を振っていると明らかにパーツが取れてる音がしたので、これは直せそうだなと思ったので分解しちゃいますwww
開け方は下記のページを参考。自分は細いマイナスドライバーで「▼」と印刷されている部分に入れると割とすんなりキャップは取れました。
っで下の写真が本体です。やはりパーツが取れてました。

どこのパーツだろと探してたら、明らかに不自然なへこみが。

金属部のハの字がちょうどぴったりだったので、ハメて上からねじ止めすればグラグラしなくなりました。
 これで直ったー!と思って外装と合わせて動作確認がしましたが、またすぐ同じ部分が取れてぐらぐらに。
これで直ったー!と思って外装と合わせて動作確認がしましたが、またすぐ同じ部分が取れてぐらぐらに。
2つ上の写真のネジを見ると赤い付着物があります。どうやら接着剤?で固定していたようですが、超音波の振動で完全にはがれてしまったようです。
ってことでみんな大好き「アロンアルファ」でねじ部と頭に接着してしばらく放置。

乾いた後、動作テストをして無事修理終了。施工してから3日たちましたが、今のところ大丈夫そうです!!
\チャンチャン/